

Automa在豆瓣标签,搜索页采集图书的实战 下载链接在文末
前言
RPA(Robotic Process Automation)是一种软件技术,通过模拟人类用户的操作来自动化重复性的业务流程任务。它在应用层面的背景是应对企业中繁琐、重复的手工操作,提高效率,减少错误,释放员工从事更有价值的工作。随着AI技术的融合,RPA正向智能化、认知化方向发展,前景广阔。
一、Automa是什么?
Automa 是用于浏览器自动化的浏览器扩展。从自动填写表格、执行重复性任务、截屏到抓取网站数据,模拟人的各种操作,能在任何应用程式上进行鼠标点击、键盘输入、读取信息等自动化操作
专注分享Automa在办公、自媒体、财务和电商领域的高功能集合工作流。
二、Automa在网页搜索上的案例分析
1.豆瓣音乐标签
完整工作流如下:
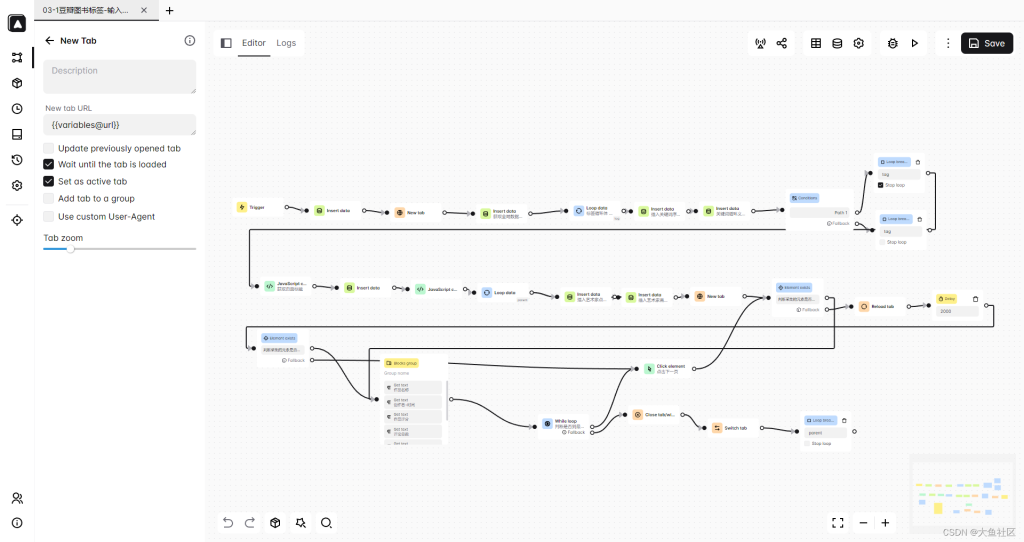
演示视频(录屏):
导出csv如果出现乱码的解决方案

背景:数据表(utf-8格式,含中文)内容导出为csv文件,打开,乱码。
原因:csv默认中文支持ANSI编码,且没有预留修改编码的选项。
解决:那只能我们修改csv的中文编码格式为ANSI了。
右键csv->打开方式->选择“记事本”(此时神奇的发现没乱码了,记事本支持utf-8)->另存为->
在弹出的窗口中选择编码‘ANSI’,名称同名,覆盖即可。
此时再打开csv,中文乱码就消失了。
这个案例
2 豆瓣图书标签工作流详解
1 打开豆瓣图书标签 网页 https://music.douban.com/tag/
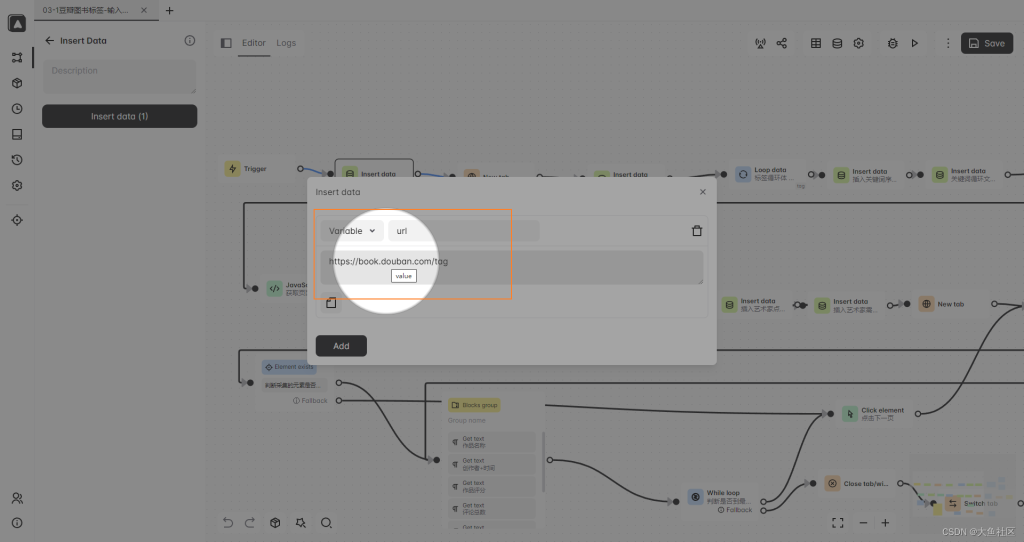
豆瓣图书标签采集的这个工作流是2023年4月份写的,写了有很长时间了,今天才过来分享。这个工作流依然可以运行,说明豆瓣的网页规则没有改变,非常感谢豆瓣。
第一步:定义一个标变量保存豆瓣图书标签的链接
第二步:
定义一个全局变量
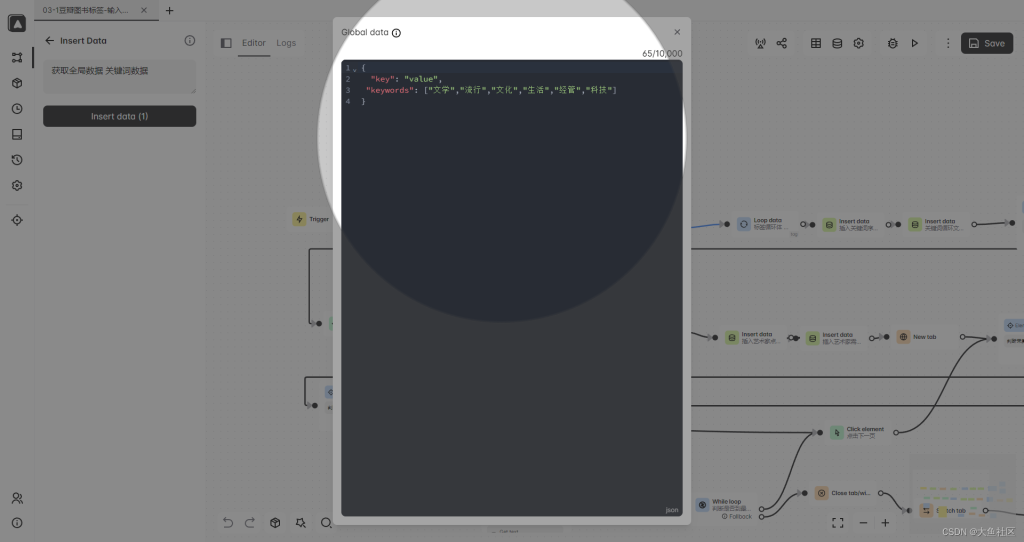
第三步
在这里做了一个判断,执行工作流,可以选择你要采集的类目
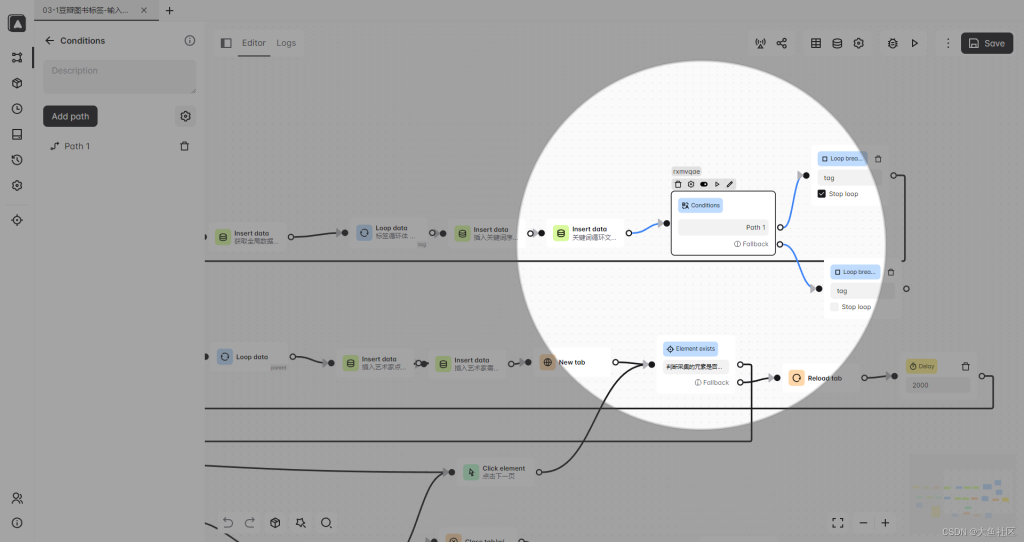
第四步
非常重要的一步,就是找到当前大类下面所有的元素。这是使用JavaScript的方式,也可以使用其他的方式。比如css元素选择等
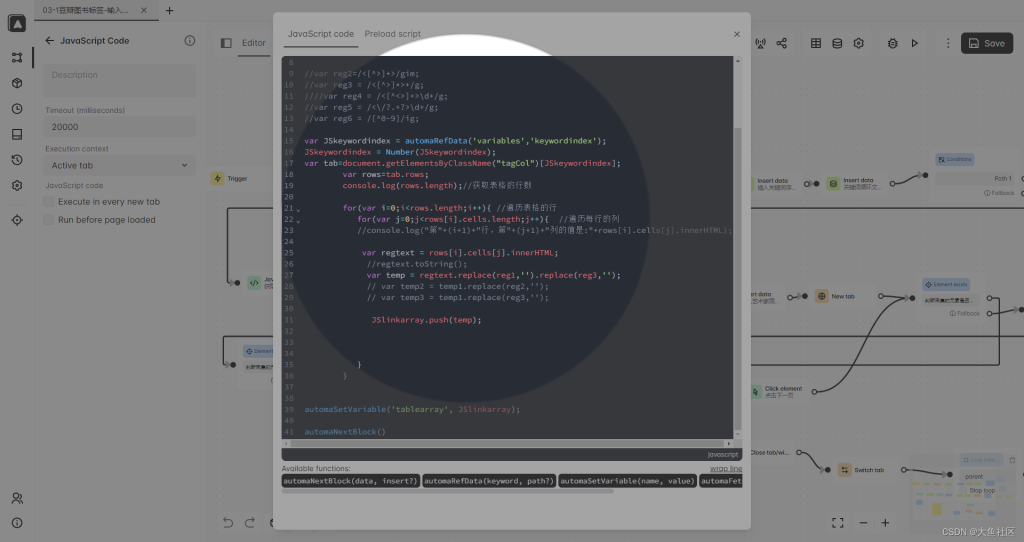
第五步:
就是具体执行按照每一个子元素就行打开爬取,红色区域就是上面第四步干的事,第五步就是把红色区域的所有元素,全部按照顺序都打开,把里面的内容全部采集。
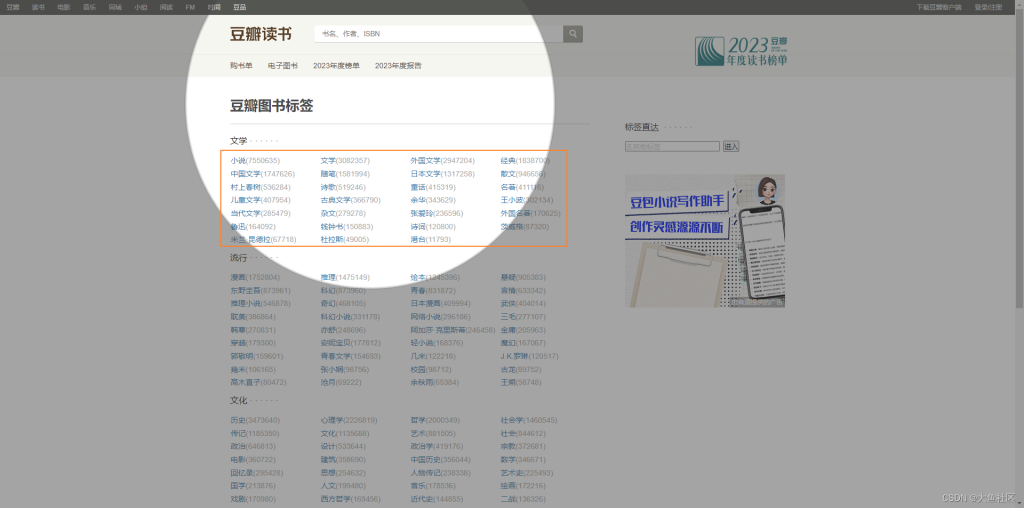
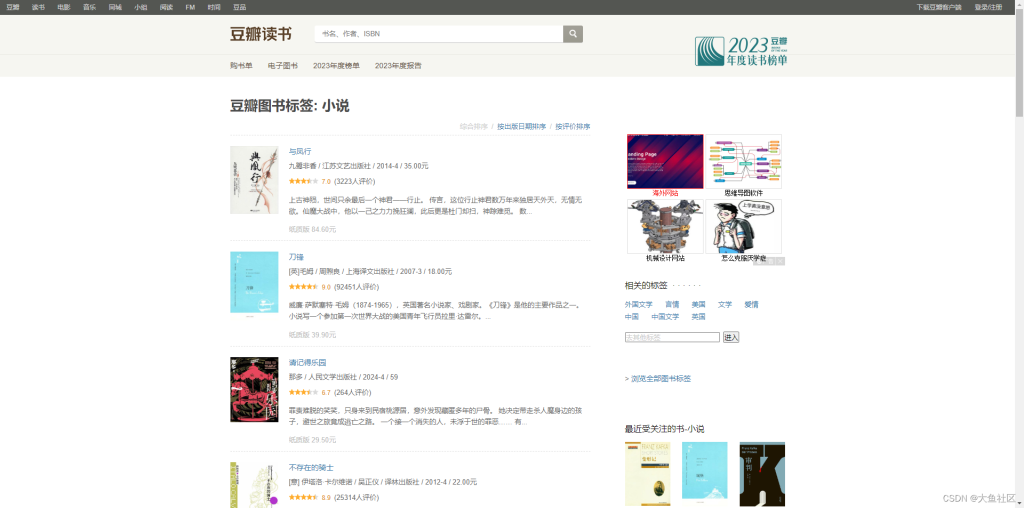
第六步
这部分就是定义你要采集的内容,也就是最终在excel表格里面需要呈现的内容,
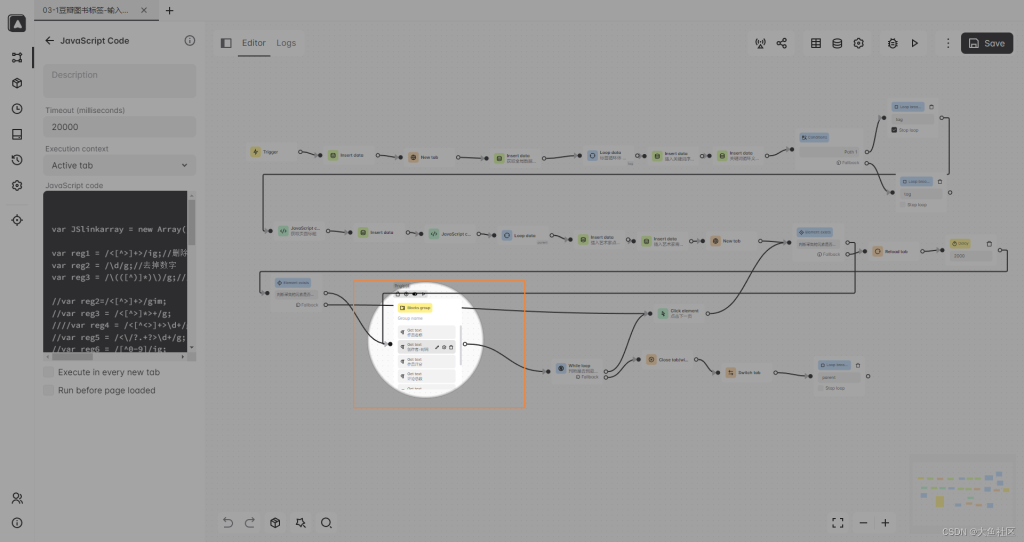
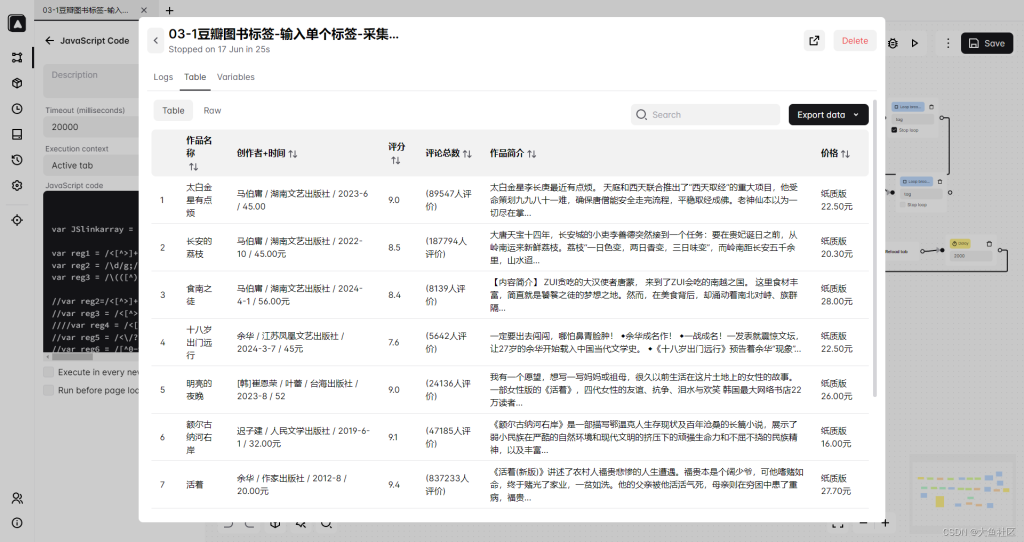
第七步
这一步是定义,一页采集完,是否需要点击下一页,所有页面点击完之后,会进入下一个元素的采集。
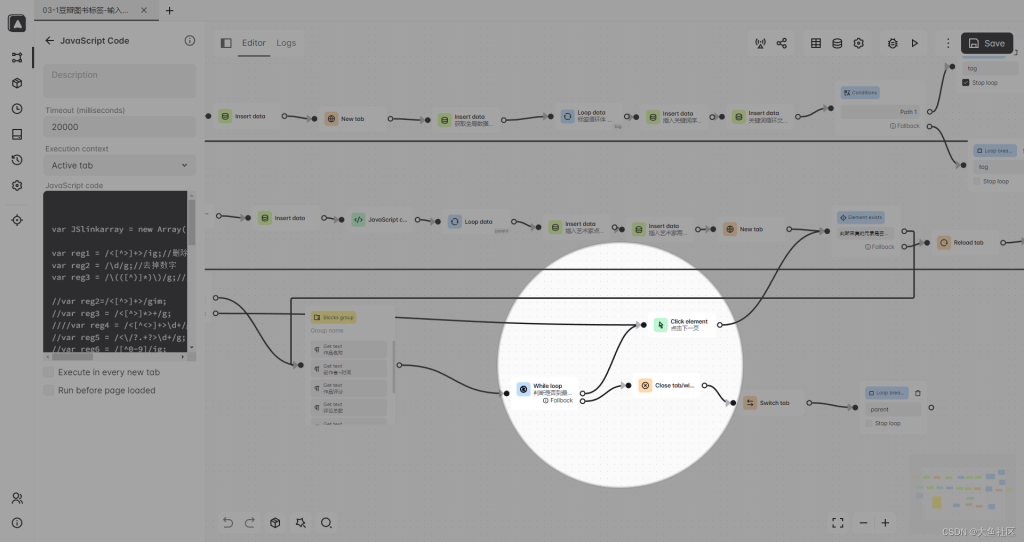
具体的工作流执行,里面的内容还是非常多的,这个部分演示图书标签的内容采集。
Automa在豆瓣标签,搜索页采集图书的实战工作流下载 请点击我下载。
总结
如果你喜欢这个文章,也喜欢Automa这个平台可以给你公司,或者你现在的项目带去帮助。欢迎交流
大鱼社区:https://hanspaul.site
\/信:sc18662470897

没有回复内容